 V době, kdy jsem si ještě užíval studentského života na VUT v Brně, jsem se účastnil konference KONDOR 2009, kterou pořádala fakulta mechatroniky TnUAD v Trenčíně. Konference se konala ve škole v přírodě Patrovec Trenčianske Jastrabie.
V době, kdy jsem si ještě užíval studentského života na VUT v Brně, jsem se účastnil konference KONDOR 2009, kterou pořádala fakulta mechatroniky TnUAD v Trenčíně. Konference se konala ve škole v přírodě Patrovec Trenčianske Jastrabie.
Můj příspěvek (ve formě PDF ke stažení ZDE) se týkal návrhu jednoduchého syntézátoru řeči. Cílem bylo vytvořit univerzální, jednoduchý a levný syntezátor, jehož výstup by byl pro trénovaného posluchače (pro posluchače, který alespoň rámcově ví, co může hlášení obsahovat) srozumitelný. Zařízení je také možné přepnout do režimu „morseovka“ a výstupem je pak text v morseově abecedě.
Blokové schéma syntezátoru je uvedeno nanásledujícím obrázku. Řečovými jednotkami, které se při syntéze zřetězují a vytváří výstupní signál, jsou fonémy a některé difony. Fonémy i difony jsou uloženy v databázi (DB), ze které jsou potom po I2C sběrnici načítány. Text je do CPU zasílán přes rozhraní USART. Řečové jednotky načítané z databáze, jsou předávány do bloku PWM (Pulse-Width Modulation). Výstupní řečový signál je už potom veden přes dolní propust [3] do nízkofrekvenčního zesilovače a reproduktoru.
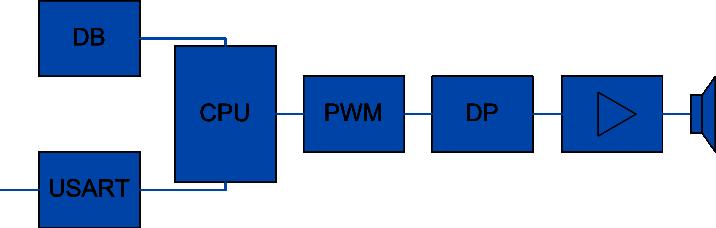
DB – databáze je tvořena 512 kB pamětí EEPROM s rozhraním I2C, řečové jednotky jsou uloženy s vzorkovací frekvencí 8 kHz
USART – rychlost 2400 Bd, asynchronní přenos, bez kontroly parity, 1 stop bit, 8 datových bitů, (rozhraní USART je součástí CPU)
CPU – mikrokontrolér Atmel AVR Mega8
PWM – frekvence výstupu je 62,5 kHz pro lepší potlačení rušení na výstupu (kvůli malé strmosti DP), (rozhraní PWM je součástí CPU)
DP – dolní propust s mezním kmitočtem 4 kHz pro odfiltrovaní vysokofrekvenčního rušení
ZESILOVAČ – nízkofrekvenční zesilovač LM386
Popis metody syntézy
Většina profesionálních řečových syntezátorů dnes používá [1] konkatenační (spojovací) metodu syntézy řeči. Řeč se vytváří spojováním úseků řeči uložených v databázi. Pokud je použita dostatečně velká databáze (je potřeba postihnout co nejvíce koartikulačních jevů mezi jednotlivými fonémy), je takto vytvořená řeč velmi dobře srozumitelná. Pro zvýšení kvality výsledné řeči se ještě často provádí modifikace prozodie (intonace, frekvence základního tónu) [1], [2].
Navržený syntezátor používá z důvodu nedostatku paměti (512 kB) jen základní fonémy a některé difony (spojení dvou fonémů). Je známo, že jednotlivé fonémy nenesou žádnou informaci o prozodii řeči a proto je také výsledná řeč hůře srozumitelná. Při vytváření jednotlivých fonémů se vycházelo z tabulky uvedené v [5].
Na srozumitelnost vytvořené řeči mělo také velký vliv určení hranic fonémů ve slovech (provádělo se ručně). Při „manuálním“ nahrávání vzorových slov nebylo možné dodržet stejný tón řeči (zhoršení srozumitelnosti řeči) a proto byla vzorová slova získána výstupem z řečového syntezátoru Epos [4]. Jednotlivé fonémy potom byly převzorkovány na 8 kHz, uloženy do formátu RAW (čistá data), spojeny do jednoho souboru a nakonec nahrány do paměti EEPROM.
Schéma zapojení a plošný spoj
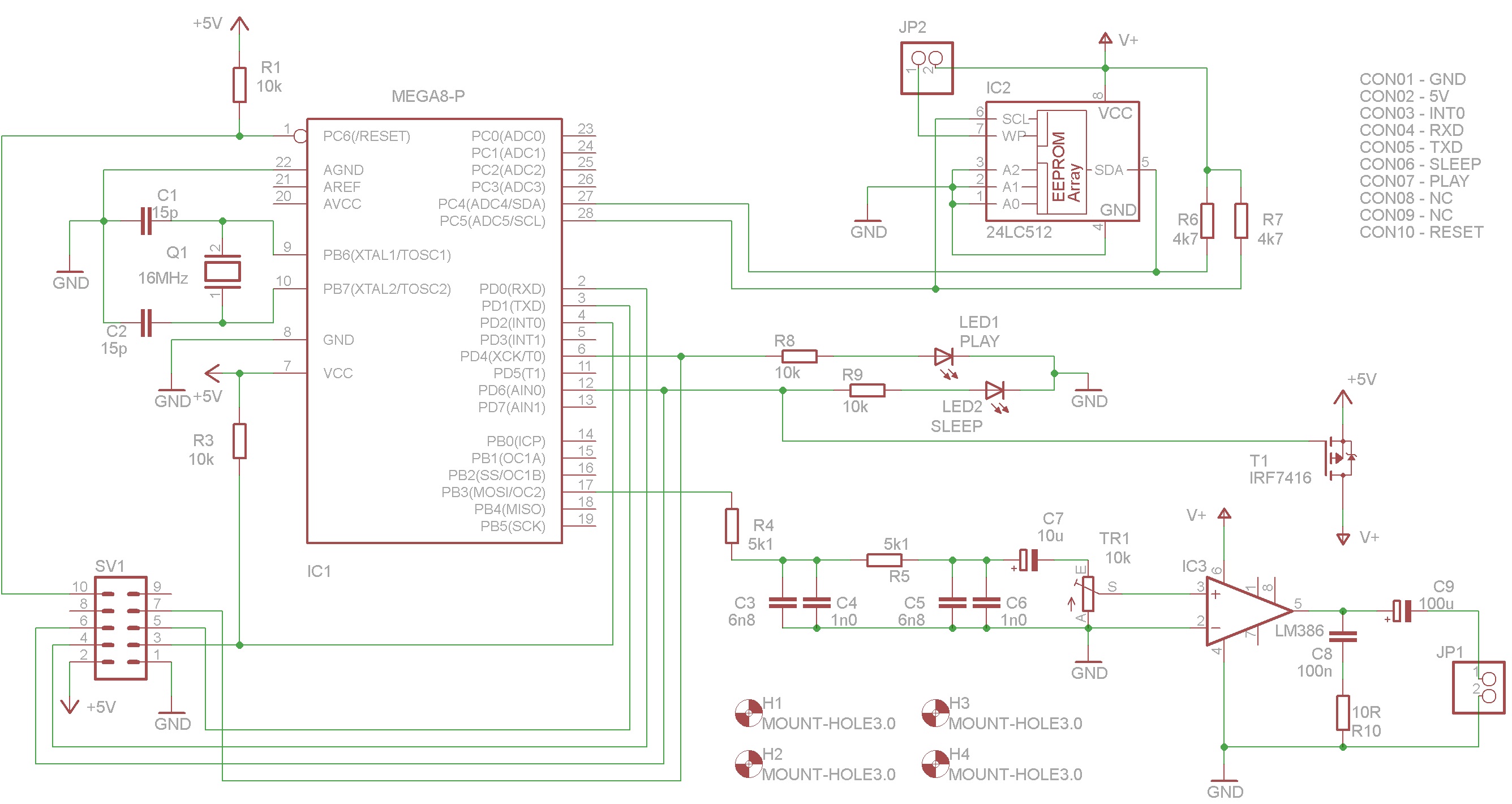

Ovládání syntézátoru
Maximální délka textu je 500 znaků. Pokud bude text kratší, je potřeba ho zakončit znakem „;“. Text může být tvořen jen malými písmeny a může obsahovat diakritiku. Čísla je nutné psát „slovně“ (pokud je využíván režim „morseovka“, je možné zadávat čísla přímo). Je možné použít tři druhy mezer „ „ (mezera), „,“ (čárka) a „–„ (pomlčka) mezera je nejdelší a pomlčka nejkratší.
Text odeslaný do zařízení může vypadat například takto:
„primi,tyvní řečový syn,tézá,tor založený na skládání fonémů;“.
Po 20 vteřinách nečinnosti se syntezátor přepne do režimu spánku. Pokud se tak stane, je ho nutné před další prací probudit (přivedením log. 0 na pin 3 konektoru SV1). Některé funkce syntezátoru je možné řídit přes rozhraní USART. Příkazy jsou uvozeny znakem mřížky a končí středníkem viz následující tabulka.
| #speak [0..255]; | rychlost mluvení (0 = nejrychlejší) |
| #morse [0..255]; | rychlost morseovky (0 = nejrychlejší) |
| #sleep [0/1]; | režim spánku zakázan / povolen |
| #state [0/1]; | morseovka / řeč |
| #setdf 1; | obnovení defaultního nastavení |
Zdrojový kód napsaný v ANSI C pro mikrokontrolér AT Mega8 si můžete stáhnout ZDE.
Obsah paměti EEPROM si společně s aplikací, kterou jsem vytvořil pro její naprogramování, můžete stáhnout ZDE.
Test kvality výstupní řeči
Pro získání představy o srozumitelnosti výstupního zvukového signálu byl proveden test srozumitelnosti. Kvalita se hodnotila podle následující tabulky:
| Stupeň | Popis |
| 5 | k porozumění není nutné žádné úsilí |
| 4 | k porozumění není nutné značné úsilí |
| 3 | k porozumění je nutné určité úsilí |
| 2 | k porozumění je nutné značné úsilí |
| 1 | srozumitelné s maximálním úsilím |
Výsledek testu, kterého se zůčastnilo 11 posluchačů shrnuje následující tabulka.
| Věta | Průměr |
| Primitivní řečový syntezátor založený na skládání fonémů. | 3,36 |
| Vysoké učení technické v Brně, ústav radioelektroniky. | 3,18 |
| Šíleně žluťoučký kůň úpěl ďábelské ódy. | 1,72 |
Jednotlivé věty si můžete přehrát a udělat si tak vlastní představu o kvalitě výstupního zvukového signálu. Test ukázal, že k porozumění je nutné větší úsilí než při běžném poslechu.
Primitivní řečový syntézátor založený na skládání fonémů.
Vysoké učení technické v Brně, ústav radioelektroniky.
Šíleně žluťoučký kůň úpěl ďábelské ódy.
Syntézátor produkuje zvukový singál, který je pro netrénovaného posluchače obtížně srozumitelný. Pro zvýšení kvality řeči by bylo nutné rozšířit databází řečových jednotek především o difony a trifony, případně použít výkonější mikrokontrolér, který by umožňoval produkci zvukového signálu s vyšší kvalitou (vyšší vzorkovací frekvence).
Použitá literatura:
[1] PSUTKA J., MATOUŠEK J., MÜLLER L., RADOVÁ V. Mluvíme s počítačem česky. Academia, 2006. 746 stran. ISBN 80-200-1309-1
[2] KLEIJN W., PALIWAL K. Speech Coding and Synthesis. Elsevier. 1995. 774 stran. ISBN 04-448-2169-4
[3] DOSTÁL T. Elektrické filtry. Skripta FEKT VUT. Brno. 2007. 137 stran.
[4] EPOS. A Open Text-To-Speech Synthesis Platform. Dostupné z <http://epos.ure.cas.cz/>
[5] POLLÁK, P. – HANŽL, V.: Tool for Czech Pronunciation Generation Combining Fixed Rules with Pronunciation Lexicon and Lexicon Management Tool. ELRA – European Language Resources Association, 2002, vol. 6, p. 1264-1269. ISBN 2-9517408-0-8.
Ahoj, skvela zrozumitelnost, ja davam 5 bodov!. Obsah EEPROM nebude na stiahnutie? posiiiiim 😉
Doplnil jsem odkaz na obsah paměti EEPROM (pod odkazem na program pro atmel). Zapoměl jsem ještě uvést, že testovací věty jsou věty co “vypadly” z Matlabu. Ve skutečnosti je kvalita ještě o trochu horší, protože dolní propust neutlumí zcela kmitočet PWM výstupu. Ve výstupním signálu pak jde slyšet slabé pískání.
No jak jsem napsal v závěru, chtělo by to větší paměť s větším množstvím fonémů, difonů a trifonů a pak výkonější procesor, který by byl schopen v reálném čase provádět i úpravy prozodie.
No možná někdy v budoucnu … 🙂
Zdravím. Narazil jsem na tuto stránku při hledání českých fonemů. Potěšila mne. Zkusmo jsem postavil. Chtěl bych se zeptat, zda je sluchem rozeznatelná rychlost mluvení v rozsahu hodnoty 0 až 255. Vrací mi to hodnotu po příkazi: 01, ale ronepoznám rozdíl v rychlosti. Pořád to zamele strašně rychle i při hodnotě 255.
Jinak pro případné zájemce o stavbu, nepovedlo se mi EE naprogramovat přes zde, autorem dodaný i2C programmer. Při stejném HW jsem do EE nahrál fonemy pomocí PonyProg. Nešlo to, tak jsem HW ani neodpojoval, stáhnul jsem PonyProg a hned nahrál.
Pepa
Po víkendu se na to podívám, vyhrabu destičku ze šuplíku, ozkouším a dám vědět.
Díval jsem se do zdrojového kódu a mělo by pomoci upravit níže uvedené řádky v “kecadlo.c” do této podoby:
Dej prosím vědět, jestli to pomohlo. Zapoměl jsem si s sebou destičku vzít do práce a týden se teď nedostanu domů, takže jsem to neměl možnost otestovat “naživo”.
Tento týden jsem řešil kód pro DS1307, takže jsem trochu na Kecadlo zanevřel. Zkoušel jsem změnit hodnoty v programu, ale jinde než uvádíš ve své odpovědi. To nepomohlo. Tento víkend vyzkouším Tvůj návrh a dám vědět.
Máš asi větší zkušenosti, tak se zeptám: Nepomohlo by více vzorků do větší paměti, třeba Flash AT45DB321? Je levnější než I2C EEPROMka a o hooodně větší (v TME). Akorát jsem nepochopil jak jsi ty fonemy tvořil :(. Byl bych ochoten se toho ujmout, pokud by to mělo smysl. A taky si začínám hrát s STM32F103.
O sériové flash paměti vím, ale tehdy jsem ji neměl k dispozici, takže jsem použil eeprom. Více vzorků = vyšší vzorkovací frekvence by určitě kvalitu řeči zlepšila, ale tehdy jsem zvolil 8khz kvůli velikosti EEPROM a hlavně kvůli výkonu ATMELU (vyšší vzorkovací frekvenci nedokázal i s vyčítátím dat z paměti a generováním PWM zvládnout).
Jak jsem psal v příspěvku, fonémy jsem ze slov extrahoval ručně. To znamená, že jsem si slova nechal namluvit syntézátorem EPOS (jde to online přes jejich stránky) a z namluvených slov jednotlivé fonémy vytáhl za pomoci MATLABU. Z něho potom vypadnul sloučený soubor a tabulka s adresami pro kód do mikrokontroléru.
Zdravím. Tak jsem to zkusil. Při 0 – stejné, moc rychle, při 1 – hodně zpomalené, huhňá, při 2 – skřeky a dále skřeky. Asi je v programu ještě nějaký problém, protože pokud zádám podruhé příkaz #speak x;, tak se neprovede a CPU zamrzne.
Příspěvek i PDF soubor jsem četl, ale nepochopil :(. To jsi preparoval z WAV namluvených souborů? Jak se pozná kde končí jednotlivé hlásky? Neznám MATLAB, jestli se to dá nějak poznat v něm.